Building a Database I - Log-Structured Merge Trees
Here is how a log-structured merge tree works and why it is an advantageous database engine with code examples.
So I have been reading Designing Data-Intensive Applications by Martin Kleppmann and got super excited about the topic of a data structure called Log-Structured Merge Trees (LSM). This database indexing mechanism is used by many NoSQL databases. Compared to the B-Tree, the widely used structure in relational databases LSMs provide different benefits. The way it operates is very intuitive and has many advantages. Cassandra and HBase both use similar systems, and it happens that I have some experience with these and was always curious what compaction, memtable, or SSTables are, but never so much to look into it in detail. This book covers this topic well and I just got motivated to implement such a database engine to better understand it. This post is about how it works and how I have implemented a very basic key-value store with it.
This post is a part of the Building a Database series, other entries include:
Related articles:
How Log-Structured Merge Trees work
I don't want to go into very much detail on all aspects here, I'll just talk about some of the more interesting parts, but a quick over is necessary for a complete understanding, so let's see how LSM works.
Adding new records to the database
As the name says it is a tree-based data structure, an ordered tree to be precise. Whenever you add a new record to an LSM database it most likely gets added to a commit log and a memtable. The commit log is just an append-only log of all operations on the database that can be used to restore data if the system crashes. To make this happen the log is stored in a file to survive in case the process or system goes down.
The memtable is an in-memory ordered tree that holds key-value pairs and is ordered by the key. I used a TreeMap in Java for this purpose wrapped in a class with some utility functions to make it look better and hide the implementation details.
public class LsmDataStore implements DataStore {
...
public void put(String key, String value) throws IOException {
DataRecord dataRecord = new DataRecord(key, value);
commitLog.append(dataRecord);
memtable.put(dataRecord);
if (memtable.getSize() > FLUSH_TO_DISK_LIMIT) {
flush();
}
}
...
}When adding new and new records and some conditions are met, for example, the memtable gets big enough it will be persisted to permanent storage (HDD, SSD, etc) as an SSTable. This SSTable serialization should create at least 2 files, an index, and a data file. The data file will store the key-value pairs from the memtable keeping the sorted order. The index file will store a sparse index of the keys and their offset in the SSTable. This index will come in handy when we are looking for values and speed up the search.
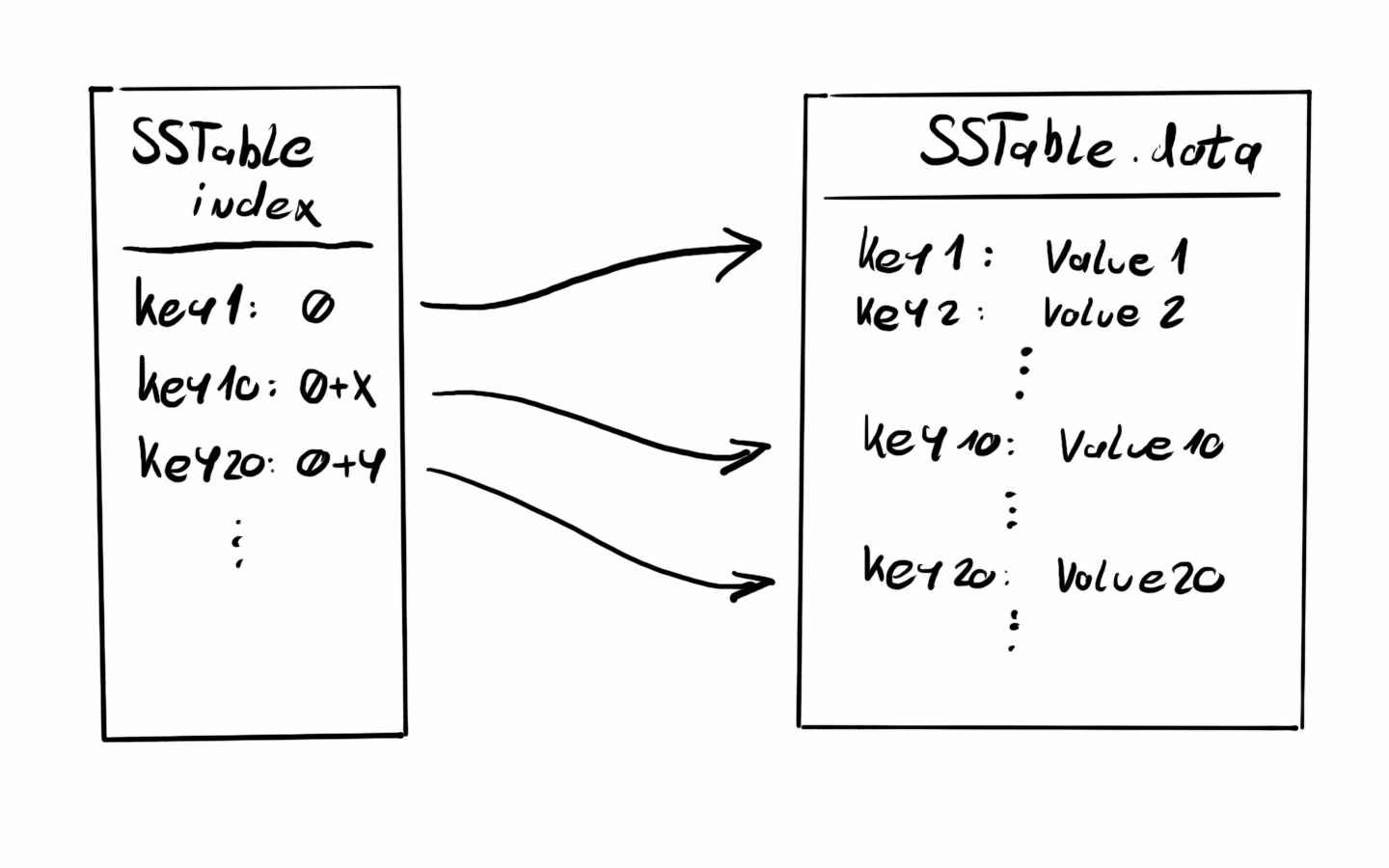
After the SSTable is written to disk, the commit log and the memtable can be cleared and writing values can continue.
public void flush() throws IOException {
ssTableManager.flush(memtable.getAsMap());
memtable.clear();
commitLog.clear();
}Creating the new SSTable is really just writing the memtable contents to a file. I chose to serialize the TreeMap with line breaks among keys and keys and values separated by :: not the most efficient but good for demonstration.
The index in my current implementation is new TreeMap where I map the original keys to a Long value representing the line number where that key is in the SSTable data file. This index structure is not a sparse one but will do for now.
public class SSTableManager {
private final List<SSTable> ssTables;
...
public void flush(Map<String, String> data) throws IOException {
SSTable ssTable = new SSTable("sstable-" + UUID.randomUUID());
ssTable.write(data);
ssTables.add(ssTable);
...
}
...
} The newly written SSTable must also be added to an in-memory list of tables so we can reference it while looking up values.
SSTables are immutable, they can't be changed once persisted, this implies some questions like how can we update a value, or how can something be deleted?
Updating and deleting values
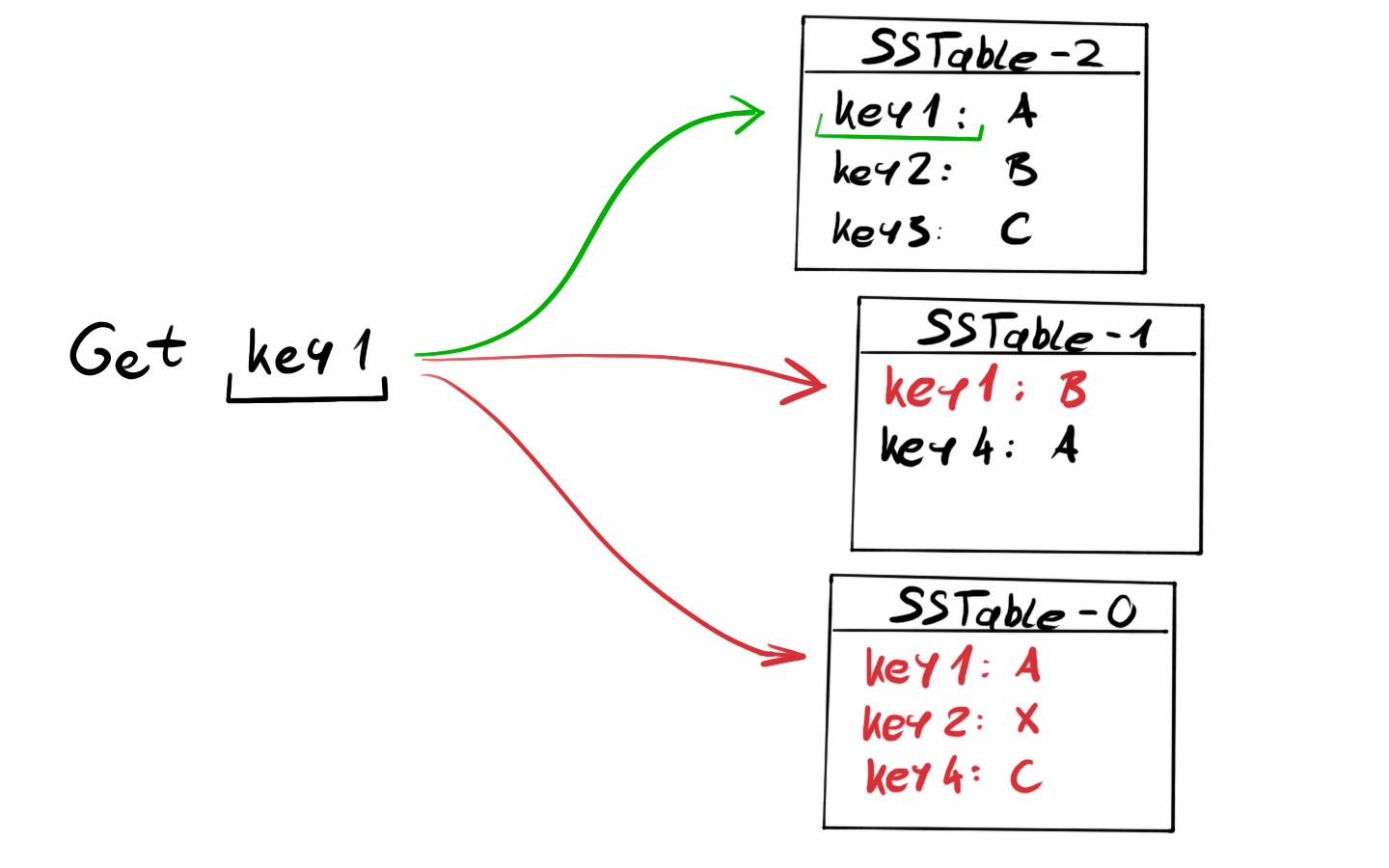
One of the key features of SSTaables and the memtable is that data is sorted by key (it is called a Sorted String Table after all). Whenever we look for a value we can start going back from the most recent record to the older ones.
To update the value for an existing key, just insert it again. The reading logic will find the newer value first and return, the old one will never be found again.
Deleting a record is similar. It is usually done by adding a new version of the key with a special value called the tombstone. The database will recognize the tombstone and handle it as a deleted item for the clients.
public Optional<String> get(String key) throws IOException {
String value = memtable.get(key);
if (value != null) {
return Optional.ofNullable(checkDeleted(value));
} else {
return ssTableManager.findValue(key).map(this::checkDeleted);
}
}
private String checkDeleted(String value) {
return TOMBSTONE.equals(value) ? null : value;
}Reading records
So as seen in the previous paragraphs we just have to start reading from the newest record to the oldest, but how exactly?
The most recent records will be in the memtable, the memtable is the new SSTable in the making, so if we are looking for a specific key, first we have to check that. If the value is there we are happy, we found it, it was in memory so it is also very fast.
If it was not in the Memtable we have to look at the SSTables. We must have a list of our SSTables in order of creation. By starting with the most recent SStable we can look at its index and check if the key we are looking for is there. If not we can go to the next SSTable and repeat.
Compaction
An interesting side effect of the immutable SSTables being written to permanent storage one after the other is that it is very inefficient after a while. When keys are updated or deleted there will be old versions in the older SSTables that are basically useless, our logic will never touch those, as we are only interested in the most recent version of a key. These dead keys just eat up space and slow our operations.
To solve this, LSM-based systems often use a mechanism called compaction. Compaction will read SSTables into memory and merge them starting from the older ones. During this merge, duplicate keys will be eliminated keeping only the most recent versions. This functionality can be triggered based on some conditions like the number of SSTables, or manually by the user.
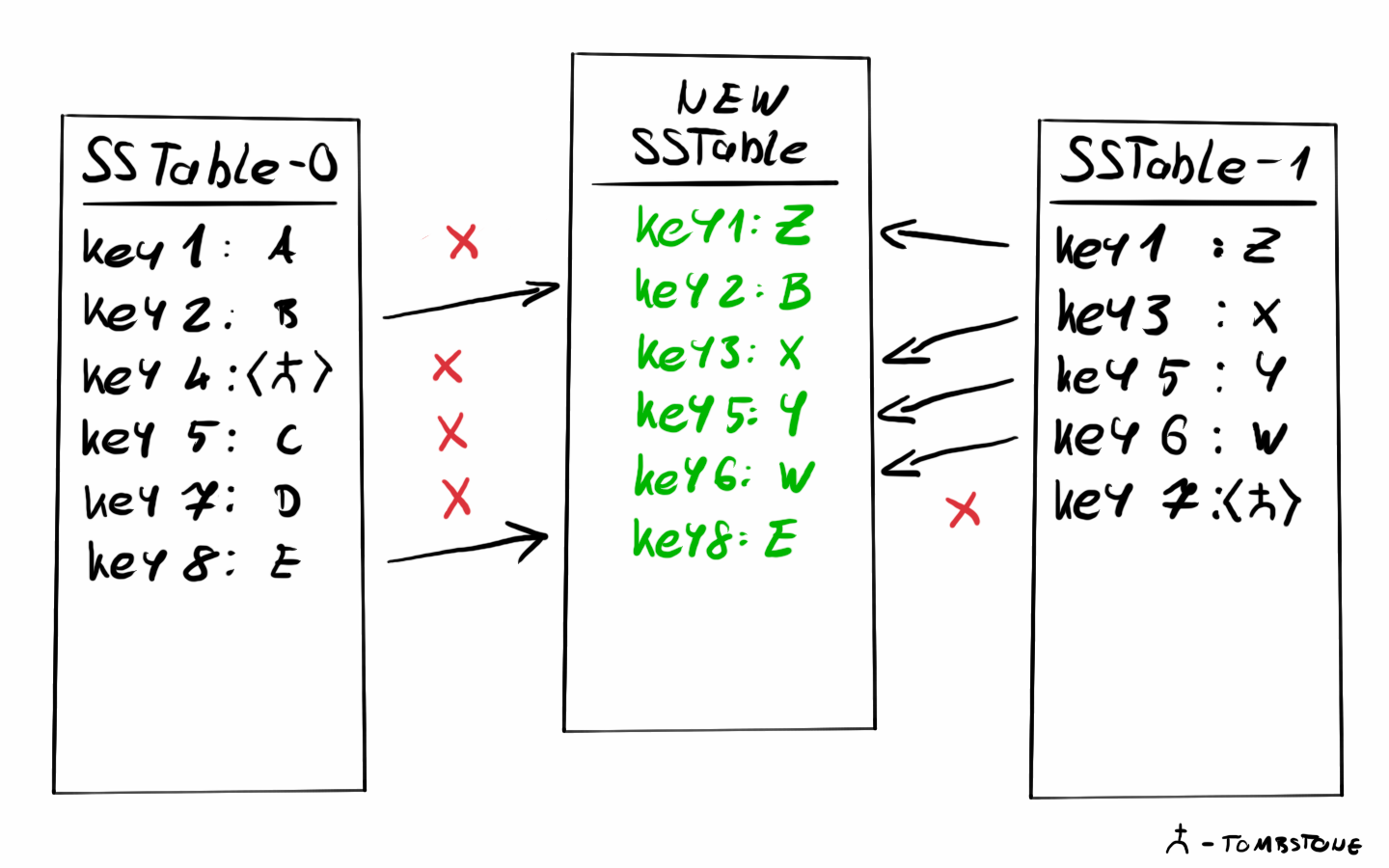
In my example, compaction will not work on SSTables bigger than a certain size. The algorithm will start looking at the tables starting from the oldest, and if one is smaller than the size limit start merging it with the next one. If the resulting table is still smaller than the limit then merge the next one into it too and so on. Once the new table is bigger than the limit add it to the new list of SSTables and go to the next not yet merged table and repeat.
public List<SSTable> compact(List<SSTable> tables) throws IOException {
List<SSTable> result = new ArrayList<>();
for (int i = 0; i < tables.size(); i++) {
SSTable table = tables.get(i);
if (table.getSize() > compactionSizeLimit) {
result.add(table);
} else {
SSTable mergedTable = table;
while (i + 1 < tables.size()
&& mergedTable.getSize() <= compactionSizeLimit)
{
mergedTable = merge(mergedTable, tables.get(i + 1));
i++;
}
result.add(mergedTable);
}
}
return result;
}The merge itself is pretty simple, similar to the last step of a merge sort. If the two values being compared are equal - the keys are the same - we will use the one from the newer SSTable since the most recent value must be used, and older keys should be discarded.
Future work
Now we know how an LSM Tree works. In the code that you can find on my GitHub page, I have implemented a very simple DataStore interface using the above-explained pure Java implementation of this data structure. The interface defines a simple put, get and delete operations. The logic in the storage engine handles finding already existing data after a restart so it can continue from where it was stopped. This however is still just a bare demonstration of how the data structure and algorithms can potentially look like.
While working on this I figured it would be good practice to handle other aspects as well like efficiency and performance. Concurrency could be a very interesting topic to look into and extend the codebase with proper handling. There are many ways to improve the functionality too, such as using a bloom filter to stop scanning all the tables for values that were never added. My intention is still not to make a new database, but to make a demonstrator and learn. In the following posts, I will take a deeper look into those problems and see what I can do about them.
The project is available on GitHub.
Some useful URLs
Here I gathered some useful material that I learned from.


