Altering SQL database schemas in production
Altering an SQL database schema in production can be tricky. This article summarizes the most common use cases and solutions.
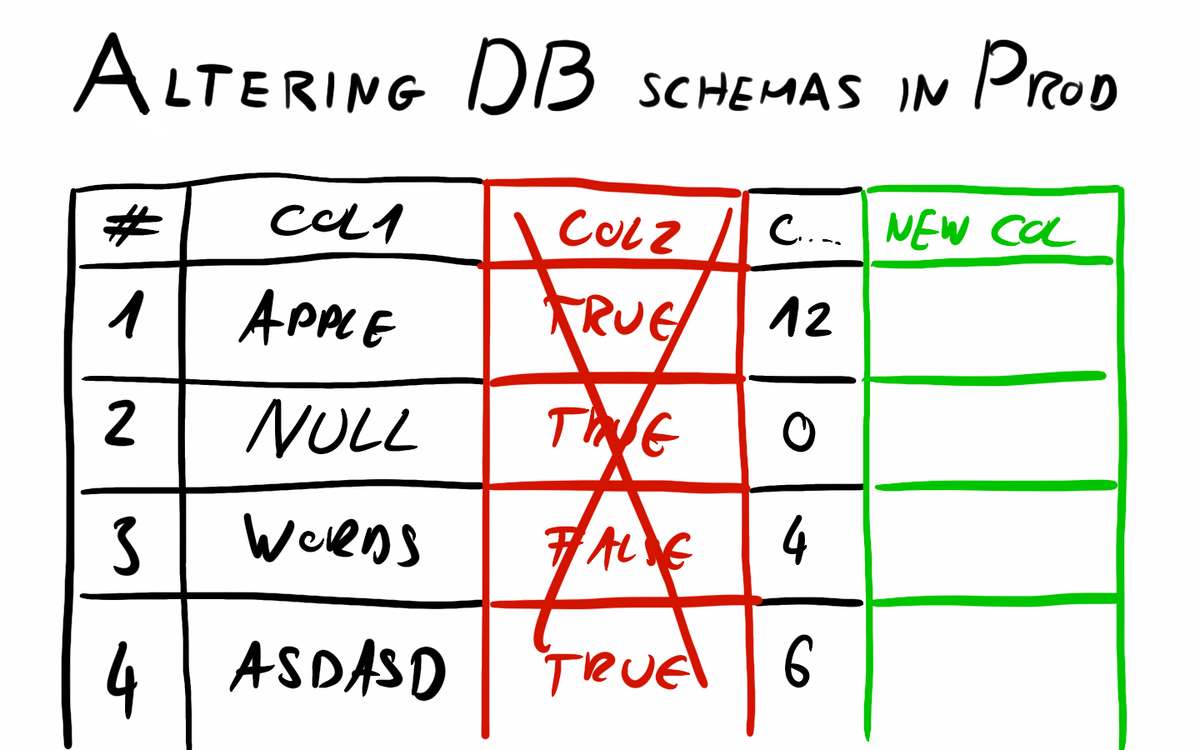
There can be many cases when you have to alter tables in an RDBMS while running in a production environment. Adding entirely new tables doesn't pose serious challenges, however, deleting a no longer needed column can be tricky. In this post, I will investigate a few scenarios and explain the hidden traps and points that must be handled with extreme care.
The system we work on
First I have to establish the system we are working with. If you have a single application instance accessing the database, most of these issues won't affect you. In a large-scale production system, there are a few things we don't want. For example, we certainly don't want:
- downtime and
- losing data
In the scenario I will talk about we will have more than one instance of our application running at all times (the title said production after all). This horizontally scalable, redundant setup is very common. Often implemented with Dockerized services running in Kubernetes.
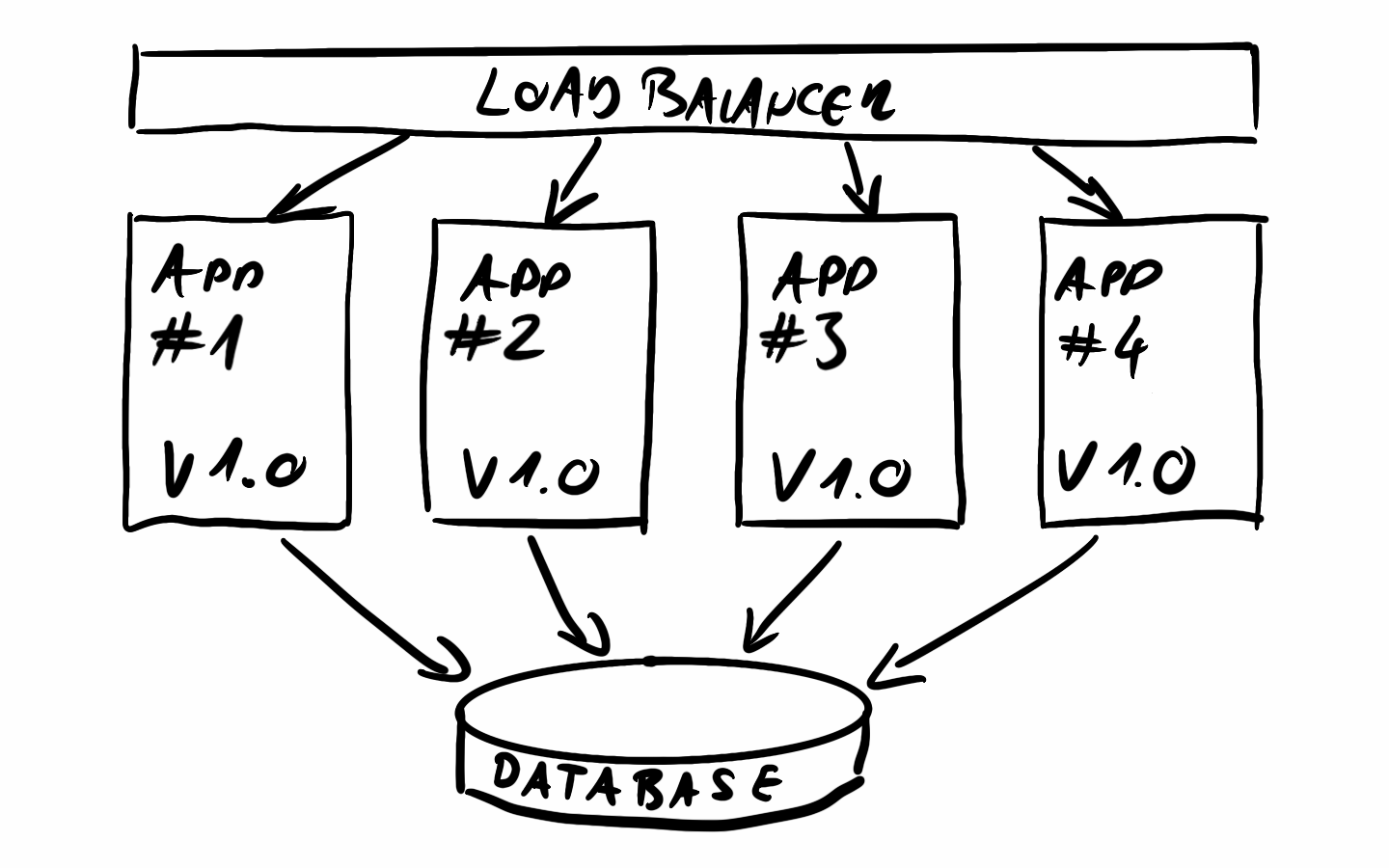
A load balancer in front of our app instances will forward the incoming requests to our running nodes. All nodes are usually stateless and are exactly the same. These instances are consenting to the same database to serve the requests.
In setups like this, new application version releases are usually executed using rolling update, meaning new instances are started with the new version, and once a new one is running an old one is getting stopped. This way we keep the number of running instances at the desired amount at all times. This also means that there will be a period - usually, a few minutes, depending on the system - when both the old and new versions of the application are running and serving requests simultaneously. This will prove to be quite a headache later for DB updates.
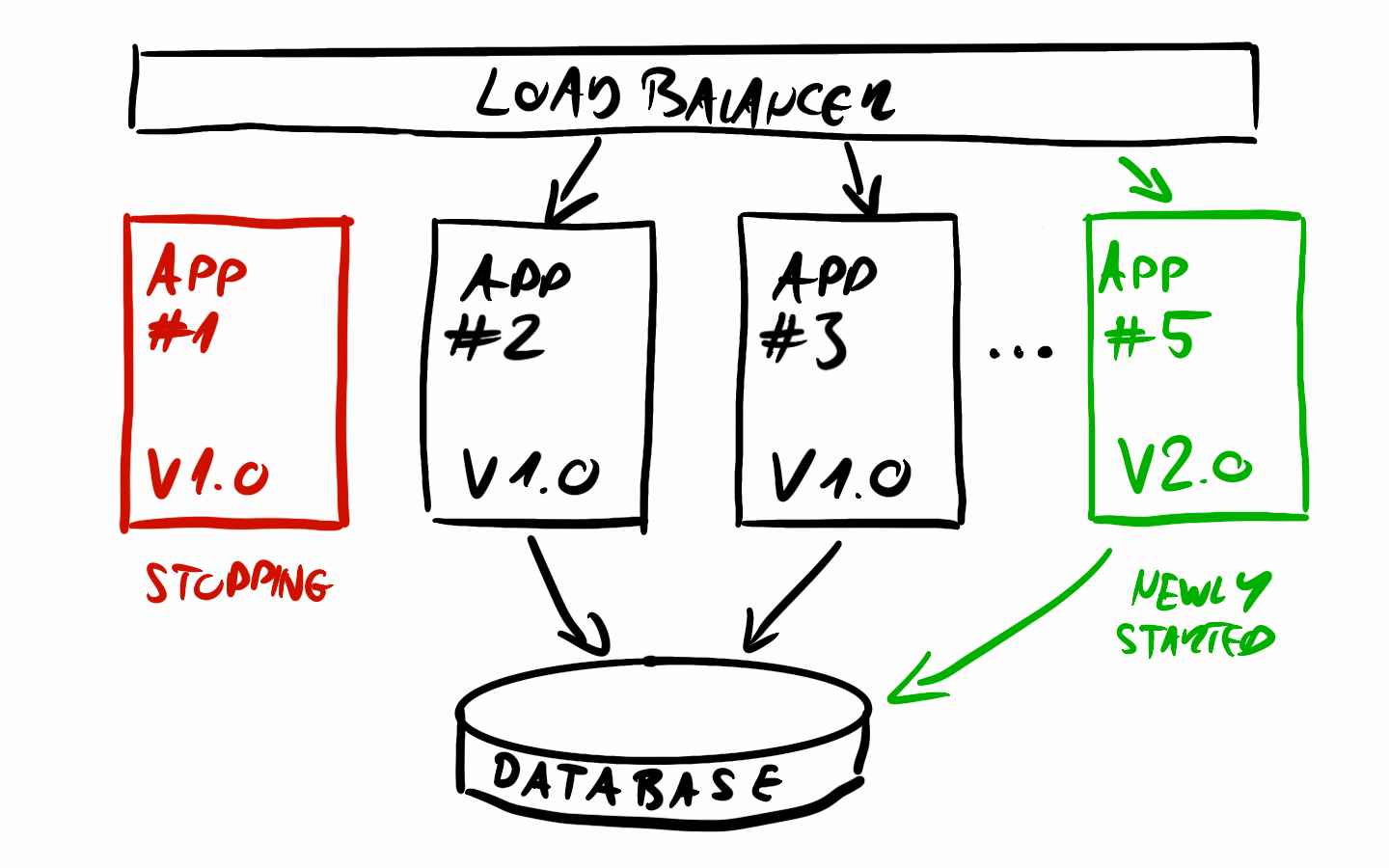
We also have to consider things like an ALTER TABLE will most likely cause an exclusive lock on the whole table, blocking even simple SELECT statements. If the ALTER TABLE statement runs for minutes, that will cause some serious issues upstream. Things like locks are handled very differently from database to database. You will have to familiarize yourself with the tech you are using (PostgreSQL locks for example), better ask the DBAs for help on how to approach a more tricky situation.
How we work
In the code we usually use an ORM framework, in the case of Java/Spring JPA+Hibernate is a very common choice. These help us a lot, for example, they can generate the DB schema DDL from code that we write for the application. However, I don't suggest using this feature except for fast prototyping. We have much more control over the database and schema changes if we use a schema versioning tool like Flyway or Liquibase. With these we can have version-controlled schemas, keeping everything nice and tidy. The database DDL and other migration scripts that we write are part of our application, stored in the same repository. Both Flyway and Liquibase integrate with Spring and can run our scripts on the application startup. This way if we want to change the database schema we will have to write a migration script, and release a new version of the app with this script in the folder for migrations. The versioning tools will do the rest for us and make sure that when the new version starts up the changes are applied.
For the use cases that will follow I assume using Hibernate with ddl-auto on validate, or not using Hibernate just raw JDBC (this can be a topic of another post). The schema is handled with a versioning tool like Flyway or Liquibase.
The changes
Adding a column
Adding a new column is the easiest of the table changes we can make. Keep in mind, that as we have discussed earlier, we are using a rolling update process to release a new version, and there is a timeframe when both old and new versions are running simultaneously.
ALTER TABLE distributors ADD COLUMN IF NOT EXISTS address TEXT;Luckily for us, when adding a new column the old versions can easily ignore the new addition. If we use native queries with JDBC we should not have any issues, and Hibernate should ignore the new columns too.
IF EXISTS / IF NOT EXISTS. They act as a safeguard and can prevent a change from happening if something is not as we have expected it to be.The only problem that can occur is that the new column we introduce is NOT NULL.
ALTER TABLE distributors ADD COLUMN IF NOT EXISTS address TEXT NOT NULL;
As our old instances don't know about this new column, they obviously won't be able to fill the new column with data, and we will have a serious amount of exceptions on our hands. Also probably this statement would fail instantly because the records already present in the database would need this new column to be filled with something.
There are at least 2 solutions to fix this.
Use default value - all the existing records will have this new default value for this column, and the old application instances can still insert new records.
ALTER TABLE distributors ADD COLUMN IF NOT EXISTS address TEXT NOT NULL DEFAULT 'Wonderland';Do the column addition in two steps - First, introduce the new column without the NOT NULL constraint. Then once all instances are updated and the new version is filling the new field correctly you can fill this column in the older records and introduce the constraint.
The first update should include the SQL DDL to add the new column
ALTER TABLE distributors ADD COLUMN IF NOT EXISTS address TEXT;The second can fill the value for older records and introduce the constraint
/* Fill in the column for older records where it is null with something meaningful in your use case */
UPDATE distributors WHERE address IS NULL address = 'Wonderland';
/* Add constraint */
ALTER TABLE address ALTER COLUMN IF EXISTS address SET NOT NULL;Deleting a column
There are 2 different cases for this, one is when the column to be dropped is nullable and the other is when it has a NOT NULL constraint.
Nullable columns
If the column is nullable the change is a relatively easy 2 step process, similar to what we have seen in the previous section.
In the first step, we don't modify the database at all, but we have to remove all references to this column from our application. No reads and no writes. Since the column is nullable it won't hurt the older instances that the new versions are not filling this value.
In the second step, we can simply drop the column.
ALTER TABLE distributors DROP COLUMN IF EXISTS address;Do DROP COLUMN delete data?
Just a fun fact that in PostgreSQL DROP COLUMN won't delete data, just makes the column invisible for SQL statements. Actual data will be deleted and thus space freed up slowly in time when rows are updated. This makes DROP COLUMN a super-fast operation which is good for our uptime, but if our goal was to free up space then we have to run a VACUUM FULL statement, which similarly to DROP COLUMN also uses an exclusive table lock, but unfortunately is not as fast. So if we don't need that space immediately it is probably better not to force the deletion.
This was the case until PostgreSQL 13, but with 14 this section was removed from the documentation. I'm not sure if this behavior has changed since I found no exact mention of it in the changelog however, the vacuuming has been tweaked quite a bit.
Please note that this may work differently in MySQL or other databases, you always have to know how the system works that you operate on.
That pesky NOT NULL
If the particular column that we don't need anymore is marked as NOT NULL then we are in for a treat. In the previous example, we could simply remove all references for the column from our application. Both reads and writes could be eliminated as neither the app nor the database counted on that we will provide a value for that field. The case is different now, what do we know?
- We can only drop the column after all references are removed from the code
- We can't remove the write references from code before we remove the
NOT NULLconstraint itself
Based on these our update will be a 3 step process:
- Remove read references from the code, writes must stay to make sure that the inserts are okay, and the old app versions have something to read as they may build on the fact that a given column is not null. We are not touching the database in the first step.
- Drop the
NOT NULLconstraint from the column and the writes from code. The column is still there, previous versions (the version from step 1 now) can still write, but reads are no longer executed, so theNOT NULLconstraint can be safely removed, without jeopardizing consistency, similarly to the writes. - As there are no more references in the code, we can finally drop the column.
Renaming columns or changing the type
Renaming a column or changing its type has a different kind of trick. In these cases there are 2 main approaches we can take:
Alter the existing column
Altering the name or type of a column can't be broken into multiple steps. We won't be able to satisfy the needs of both the previous and new app versions trying to access the column with 2 different names or with different types. Because of this, the rolling update method won't work and we will have to stop all instances of the application completely, and start the new versions once the old ones have stopped. This means some downtime will be unavoidable. We will have to think over if this is okay for us or we have to go with the second option.
Create a new column with the new name/type and copy data from the old one
As the title says, in this method we create a completely new column (or even table) copy over the data, and switch over to the new one with the desired columns. The problematic part is the time window when we have already created the new column, copied over the existing data, but the app has not been switched over and it still fills and updates the old column. This will cause the new column to fall out of sync pretty fast. The solutions are not that obvious, unfortunately. You can try triggers, or modifying your application to write both tables at the same time. Neither is super efficient or nice.
In scenarios like this, we should consider if we can afford some downtime, or how important our change really is.
Conclusions
So what conclusions can we draw after seeing all these difficulties with altering a database table that is already in production use?
- Think and design thoroughly - try to discover as much about the domain as possible to be able to design a database table that will not have to be changed, or at least not too often. The best part is no part as Elon Musk says, it can be translated in this context as the best change is no change.
- If there are uncertainties or a schema that will change - consider storing uncertain data in a JSON type column. Modern RDBMS engines have pretty solid JSON capabilities, it can be a good compromise. If most of your data is like this, consider some kind of a NoSQL solution, maybe that suits your use case better.
- Version your schema - use a tool like Flyway or Liquibase to manage changes. You should always define the data structures and write the DDL, don't let the ORM do it for you.