Java File writing I/O performance
Boost Java file writing performance by choosing the right I/O method. Learn how BufferedWriter, FileChannel, and RandomAccessFile impact speed, durability, and efficiency—plus how I achieved a 4x faster commit-log write in my LSM tree database. 🚀

There are many ways we can write data to files in Java. As I was experimenting a bit with performance in my previous article I just realized how huge the performance differences can be. Choosing the correct way for your use case is paramount if we want to write efficient code. In this post I'll explore the ways we can write to files with their advantages and disadvantages and best fitting use cases.
I'll also demonstrate performance improving changes in my databases project where I applied the knowledge I gathered for this post. Amongst others I refactored the way I write to the commit-log, and saw 4x speed improvements.
Streams and Writers
In Java's traditional java.io package, we find several XXXOutputStream classes designed for writing byte-based data. These are fundamental for interacting with various output destinations. However, when working with files, we often deal with text. This is where the XXXWriter classes come in. These character-based classes typically wrap an underlying OutputStream, providing a more convenient interface for handling text. They abstract away the complexities of character encoding, automatically converting characters to their corresponding byte representations before passing them to the underlying byte stream for writing.
For performance reasons, especially when writing frequently, buffering is crucial. The overhead of repeatedly accessing the file system for each write operation can be substantial. To mitigate this, Java provides buffered stream and writer classes: BufferedOutputStream and BufferedWriter. These classes enhance their unbuffered counterparts by introducing an internal buffer. Instead of writing each piece of data directly to the destination, they accumulate data in the buffer. Only when the buffer is full, or when a flush() operation is explicitly called, is the buffered data written to the underlying stream or file. This drastically reduces the number of I/O operations, leading to significant performance gains.
The way we construct these objects clearly demonstrates their relationship. For example, to create a buffered character stream for writing to a file, we would typically chain the classes together:
BufferedWriter bw = new BufferedWriter(new FileWriter(new FileOutputStream("file.txt")));FileWriter (Buffered, Character-Based)
✅ Best for: Writing small text files with automatic buffering.
❌ Avoid if: You need binary data or high performance.
try (FileWriter writer = new FileWriter("file.txt", true)) {
writer.write("Hello, World!\n");
}
BufferedWriter (Buffered, More Efficient for Large Text)
✅ Best for: Writing large text files with fewer disk I/O operations.
❌ Avoid if: You need binary data or instant durability.
try (BufferedWriter writer = new BufferedWriter(new FileWriter("file.txt", true))) {
writer.write("Hello, World!\n");
writer.flush(); // Data is written to OS page cache, not necessarily to the disk immediatley
}
Channels
In Java's newer nio package we got Channels. Channels (like FileChannel) are a different way of interacting with files altogether. They don't directly deal with character or byte streams in the same way. A FileChannel works with ByteBuffers (which hold bytes). You could, however, use a Charset to encode characters into a ByteBuffer and then write that ByteBuffer to the file via a FileChannel. So, while channels work with bytes, you can integrate character encoding into that process if needed. Channels offer more low-level control and can often be more efficient, but they're not built "on top" of streams. They are a separate, parallel API for file I/O.
FileChannel (High-Performance I/O)
✅ Best for: Large file writes, memory-mapped I/O.
❌ Avoid if: You need simple appends or text writing.
try (FileChannel channel = FileChannel.open(Paths.get("file.txt"),
StandardOpenOption.CREATE, StandardOpenOption.WRITE, StandardOpenOption.APPEND)) {
ByteBuffer buffer = ByteBuffer.wrap("Hello, World!\n".getBytes());
channel.write(buffer);
channel.force(true); // Ensures durability, forces direct write to file
}
MappedByteBuffer (Memory-Mapped File, Ultra-Fast)
✅ Best for: Writing frequently to large files with minimal disk I/O overhead.
❌ Avoid if: You need immediate durability or work with small files.
RandomAccessFile raf = new RandomAccessFile("file.txt", "rw");
FileChannel channel = raf.getChannel();
MappedByteBuffer buffer = channel.map(FileChannel.MapMode.READ_WRITE, 0, 1024);
buffer.put("Hello, World!\n".getBytes());
buffer.force(); // Ensure data is written
Files.write() (Simple & One-Shot Writes)
✅ Best for: Writing small files in one go.
❌ Avoid if: You need high performance or frequent appends.
Files.write(Paths.get("file.txt"), "Hello, World!\n".getBytes(), StandardOpenOption.APPEND);
Others
I also want to mention some other options here that don't necessarily belong to either a stream or channel based category. RandomAccessFile for example gives us random access into a file. I used this option to improve read performance for SSTables in my previous post.
RandomAccessFile (Fast Appends, Explicit Sync)
✅ Best for: Commit logs, append-heavy workloads with durability.
❌ Avoid if: You prefer simpler file handling.
RandomAccessFile raf = new RandomAccessFile("file.txt", "rw");
raf.seek(raf.length()); // Move to end for appending
raf.writeBytes("Hello, World!\n");
raf.getFD().sync(); // Ensures data is on disk
raf.close();
I'm sure there are many others, but these are the most common from the standard package.
Comparison of the writing options
The below table summarizes the most important properties of these classes. Based on our use case we can choose which one to use as I will show through 3 examples in the next section.
| Method | Buffered? | Appends? | Durability Control? | Performance | Best Use Case |
|---|---|---|---|---|---|
FileWriter |
✅ Yes | ✅ Yes | ❌ No | 🟠 Slow | Small text files |
BufferedWriter |
✅ Yes | ✅ Yes | ❌ No | 🟡 Medium | Large text files |
Files.write() |
❌ No | ✅ Yes | ❌ No | 🔴 Slow | One-shot writes |
RandomAccessFile |
❌ No | ✅ Yes | ✅ Yes (sync()) |
🟢 Fast | Commit logs |
FileChannel |
✅ Yes | ✅ Yes | ✅ Yes (force()) |
🟢 Fast | High-performance I/O |
MappedByteBuffer |
✅ Yes | ❌ No | ❌ No (OS flushes) | 🟢 Very Fast | Frequent large writes |
Improving database performance by optimizing read and write operations
In my Log-Structured Merge Tree implementation that I continuously evolve there are quite a few points where I have to interact with files. The most performance sensitive ones were worth improving on. In the following section I'll show you how I managed to apply the above knowledge for these use-cases.
Writing the commit log
This is a synchronous operation and must happen for every insert into the database to guarantee durability in case of a crash. This small append to the commit log, if slow has a huge impact on data insertion performance. I checked the profiler how the time is spent in commit log writing. It confirms that it spends 95% of the time with the actual Files.write() call, so any improvement there could mean substantial gains.
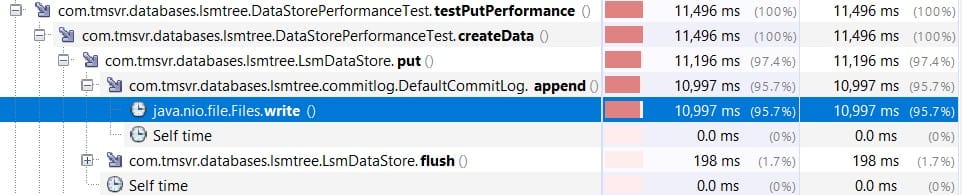
The requirements we have:
- We must be able to append lines to a file
- We want to control when the data is actually saved to disk to provide durability. Some batching is okay for performance reasons, but we must be in control.
Based on the comparison table above one of the best options is the FileChannel. It is buffered and capable to append to a file. We can force the write to the disk anytime and it was designed for high performance operations.
I replaced the earlier used Files.write() based solution in code:
public void append(DataRecord<K,V> entry) throws IOException {
Files.write(Paths.get(FILE_PATH), entryToString(entry).getBytes(), StandardOpenOption.APPEND);
}To a FileChannel based implementation:
public void append(DataRecord<K, V> entry) throws IOException {
byte[] data = entryToString(entry).getBytes();
ByteBuffer buffer = ByteBuffer.wrap(data);
fileChannel.write(buffer);
writeCount++;
if (writeCount >= FLUSH_THRESHOLD) {
fileChannel.force(false); // Metadata updates not forced (faster)
writeCount = 0;
}
size++;
}The code does become a bit more involved when using FileChannel. First, the data needs to be encapsulated within a ByteBuffer before being passed to the FileChannel.write() method. While this method performs the transfer of data, the actual write to the physical disk is typically deferred until the force() method is explicitly called. I introduced batching for the actual I/O operation. I collect FLUSH_THRESHOLD number of items in the buffer and flush once it is full. This batching of writes is a key optimization technique for improving performance.
I conducted performance measurements with varying batch sizes (10, 100, and 1000). When write() is called, the data is generally added to the operating system's in-memory page cache (not necessarily a "page file" in the Windows sense, as the wording might imply). If the application crashes before force() is called, the operating system might still write this cached data to disk eventually. However, this is not guaranteed. A power loss or an operating system crash will result in data loss. While this potential data loss is a trade-off, the performance gains from batching can be substantial.
Here are the measurement results of running the put performance tests 5 times and averaging the results:
| Method | Batch Size | Time (seconds) |
|---|---|---|
Files.write |
N/A | 40.02 |
FileChannel |
10 | 56.00 |
FileChannel |
100 | 14.50 |
FileChannel |
1000 | 7.95 |
The FileChannel approach with a batch size of 10 was, surprisingly, slower than the Files.write method. This is likely because, although Files.write appears to perform individual writes, it doesn't necessarily force the operating system to immediately persist the data to disk. The data might still reside in the OS cache and be vulnerable to loss in a crash. On the other hand, the FileChannel.force() method does guarantee that the data is persisted to disk (or at least to a stable storage medium). This additional guarantee of data durability comes with a cost. As the batch size increases, this overhead is amortized across more records, and the performance benefits of batching with FileChannel become clearly evident, demonstrating significant gains.
Serializing the Memtable to SSTable on the disk
When the Memtable in an LSM reaches a certain size it must be flushed to disk as an SSTable. In my LSM implementation this is a synchronous operation and while happening you can't insert new items into the database. This is why write performance here is crucial. Unlike the commit log where we have to append to a file line by line in separate "transactions", here we have to serialize a larger object to a file all at once.
In my previous article I already showed how I refactored this code to use a BufferedWriter instead of the Files.write method. I don't want to repeat myself too much. FileChannel would also be efficient here, we would have a bit more control, but BufferedWriter is good enough for this. I did test both solutions and the performance was technically the same in my scenarios.
Fetching data from SSTables
SSTables are the largest files managed by this kind of a datastore (100-200 MB). Reading something from the middle of it can be resource intensive and time consuming if done incorrectly. I also explored this topic and did significant performance improvements on SSTable data lookups by using RandomAccessFile instead of Files.seek and Files.read. You can read about this in more detail here.
Summary
Efficient file writing is crucial for performance-sensitive applications. This post explores different ways to write data to files in Java, comparing their advantages, use cases, and performance trade-offs. It highlights how buffered operations reduce I/O overhead, and why options like BufferedWriter, FileChannel, and RandomAccessFile are better suited for different scenarios.
Applying this knowledge, I optimized commit-log writes in my LSM tree database implementation, replacing Files.write() with a FileChannel-based approach. By batching writes and strategically calling force(), I achieved up to a 4x speed improvement.
Key takeaways:
- For simple writes → Use
BufferedWriterorFiles.write(). - For large files → Use
BufferedWriterwith manual flushing. - For performance-sensitive writes → Use
FileChannelwith batchedforce(false). - For durable commit logs → Use
RandomAccessFilewithsync()or a batchedFileChannel.force(false). - For ultra-fast writes → Use
MappedByteBuffer, though durability isn’t guaranteed.
Understanding how Java handles buffering and durability ensures optimal performance without unnecessary disk I/O. 🚀
The code is available on GitHub.